DeepSeek-R1 LLM Reasoning via RL

Introduction
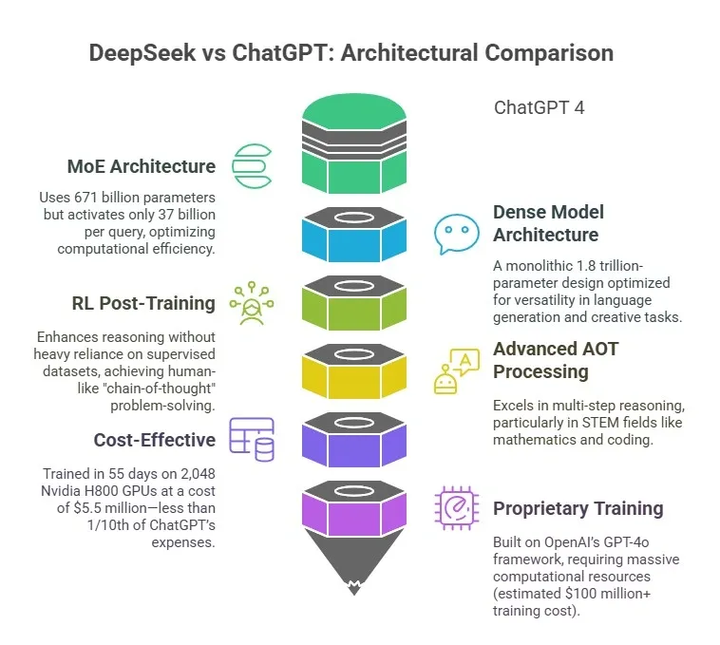
The DeepSeek-R1 model, developed by the DeepSeek-AI team, represents a significant leap in enhancing the reasoning capabilities of large language models (LLMs) through reinforcement learning (RL). This paper, titled DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, introduces two models: DeepSeek-R1-Zero and DeepSeek-R1, which demonstrate remarkable performance in tasks requiring complex reasoning, such as mathematical problem-solving and code generation.
Background and Motivation
Reasoning is a cornerstone of artificial general intelligence (AGI). While models like OpenAI’s o1 series have shown promise in reasoning tasks, their methodologies remain opaque. DeepSeek-R1 addresses this gap by exploring whether RL alone can enhance reasoning without relying on supervised fine-tuning (SFT). The results are groundbreaking, showcasing the potential of RL to autonomously develop advanced problem-solving strategies.
Model Architecture and Training Methodology
DeepSeek-R1-Zero: A Pure RL Approach
DeepSeek-R1-Zero is trained exclusively using RL, without any supervised data. The model employs the Group Relative Policy Optimization (GRPO) algorithm, which encourages the model to generate multiple solutions and rewards based on correctness and formatting. For instance, in the AIME 2024 math competition, DeepSeek-R1-Zero achieved a correctness rate of 71%, which improved to 86.7% with majority voting (cons@64). This demonstrates the model’s ability to self-reflect and generate detailed reasoning processes.
DeepSeek-R1: Enhanced with Cold-Start Data and Multi-Stage Training
DeepSeek-R1 builds on R1-Zero by incorporating a small amount of high-quality cold-start data for initial fine-tuning. The training process involves four stages:
- Cold-Start: The model is fine-tuned with data containing detailed reasoning processes.
- RL with Language Consistency: RL is applied with additional rewards for language consistency to avoid mixed-language outputs.
- Rejection Sampling and SFT: The model generates a large dataset (600k reasoning and 200k non-reasoning examples) for further fine-tuning.
- Comprehensive RL: A final RL stage optimizes the model for safety and versatility.
DeepSeek-R1 achieves performance comparable to OpenAI’s o1-1217, with a 79.8% correctness rate on AIME 2024 and a 97.3% score on MATH-500. It also excels in code generation, achieving an Elo rating of 2029 on Codeforces, surpassing 96% of human participant.
Knowledge Distillation: Empowering Smaller Models
DeepSeek-R1’s success extends to smaller models through knowledge distillation. By fine-tuning open-source models like Qwen and Llama using data generated by DeepSeek-R1, smaller models achieve competitive performance. For example, a 7B Qwen model achieves a 55.5% correctness rate on AIME 2024, outperforming larger models like QwQ-32B-Preview.
Performance and Benchmarking
DeepSeek-R1 has been rigorously tested against leading models like Claude-3.5 and GPT-4o. Key results include:
- Reasoning Tasks: DeepSeek-R1 matches OpenAI’s o1-1217, outperforming other models.
- Knowledge Tasks: Scores of 90.8% on MMLU and 71.5% on GPQA Diamond highlight its robust knowledge capabilities.
- General Tasks: Achieves an 87.6% win rate on AlpacaEval 2.0 and 92.3% on ArenaHard, demonstrating versatility.
Challenges and Future Directions
Despite its success, DeepSeek-R1 faces challenges such as language inconsistency in non-English contexts and limited performance in software engineering tasks. Future work will focus on improving multi-turn dialogue capabilities, expanding language support, and enhancing domain-specific performance.
Conclusion
DeepSeek-R1 is a game changer in AI, displaying how reinforcement learning can help improve reasoning abilities in large language models all on its own. Its unique design, along with knowledge distillation, offers a flexible and budget-friendly option for a wide range of uses. As AI keeps developing, DeepSeek-R1 raises the bar for reasoning skills, paving the way for smarter and more autonomous systems.